The IPUMS Project: An Update1
by Matthew Sobek and Steven Ruggles
Go Back to IPUMS Documentation Index
The Integrated Public Use Microdata Series (IPUMS) is a coherent national database describing the characteristics of 55 million Americans in thirteen census years spanning the period from 1850 through 1990. It combines census microdata files produced by the Census Bureau for the period since 1960 with new historical census files produced at the University of Minnesota and elsewhere. By putting the samples in the same format, imposing consistent variable coding, and carefully documenting changes in variables over time, the IPUMS is designed to facilitate the use of the census samples as a time series. The database includes comprehensive and comprehensible documentation amounting to some 3000 pages of text, including detailed analyses of the comparability of every variable across every census year. Both the database and the documentation are distributed through an on-line data access system at http://usa.ipums.org/usa/, which provides powerful extraction and search capabilities to allow easy access to both metadata and microdata. The project is funded by the National Science Foundation and the National Institutes of Health, so all data and documentation are available without cost.2
The characteristics of the IPUMS samples are detailed in Table 1.3 The only census years missing from the series are 1890, which was destroyed by fire, and 1930, which is still subject to 72-year census confidentiality rules. In 2002, it will be practical to add 1930 to the series. For most years prior to 1970, we have a one-percent random sample of the population. In several cases-1860, 1870 and 1900-the preliminary versions of the samples now available are smaller, but each will eventually contain one percent of the population. The only remaining sample of lower density is 1910, and we plan to begin a project soon to expand that sample. Thus by 2007, we expect to have collected-in a consistent manner-samples of at least 1-in-100 density for every possible census year since 1850.4
The early samples are much smaller than recent ones, partly because the population was smaller. Moreover, the sample density available for the period since 1970 is much higher than in earlier census years: for each of the past three censuses, we have microdata on at least six percent of the population, which allows analysis of very small population subgroups. The census also tended to ask more questions over time, as indirectly shown by the column in Table 1 for the number of variables. Although the earlier samples are smaller and less detailed than their modern counterparts, they are still the largest and richest sources available for quantitative historical research in that period, and are capable of supporting research on topics ranging from marriage and fertility to social stratification and household structure.
The Minnesota Historical Census Projects contributed a Special Issue to this journal in winter 1995. That issue explained our procedures for creating new historical samples of the 1850, 1880 and 1920 censuses, and introduced the first full version of the IPUMS, which was released that year. Our discussion of the IPUMS included an overview, review of original sample designs, a procedure for estimating sampling errors, and articles on two of the most complicated new features of the database: the common occupational classification and constructed family interrelationship variables. The current issue aims to cover somewhat different ground. This introduction provides a short history of the ongoing IPUMS project, where it stands at present, new features and improvements added since our 1995 release, and what we hope to accomplish in the next few years. Separate articles describe the IPUMS documentation and data extraction system in detail. Additional articles discuss procedures for creating new historical census samples at the University of Minnesota. Topics include the new 1860 and 1870 census samples, the 1910 Black and Hispanic oversamples, our evolving procedures for interpreting census manuscript responses, and techniques for identifying metropolitan areas.
Brief History of the Project
We have been working with the national historical census samples since the first of them-the original 1900 Public Use Sample-was created by Samuel Preston. By the mid-1980s, national historical census samples existed for 1900, 1940, and 1950. In addition, the Census Bureau had created samples for 1960, 1970 and 1980 as part of the decennial enumerations. To carry out research on long-run social and economic change (e.g. Ruggles 1988, Stevens 1990, Ruggles and Goeken 1992, McCaa 1993) we developed software to recode a subset of variables from these six census years into a common format. The variables were a crude lowest common denominator of the six census years, and the documentation was minimal. Nevertheless, our common-format extracts began to develop a following, first among faculty and students at the University of Minnesota and then among researchers at other institutions. Soon we found ourselves constructing hundreds of customized data extracts for researchers at Minnesota and elsewhere.
Not everyone, of course, used these crude datasets. Our efforts combining, recoding, and winnowing these large files were replicated at various data centers across the country. This not only represented a considerable duplication of labor, but the complexity of the data and inconsistent documentation invited errors. The basic problem was that the census samples were never designed with compatibility in mind. The difficulties include differing sampling methods, record layouts, variable coding and uneven documentation. And the census itself changed over time, asking new questions, dropping others, or altering their wording. Before the IPUMS, even our best efforts at designing common format extracts only mitigated these problems and were never more than piecemeal. We learned a great deal in the process, however, and became convinced that a more thorough and well-documented concatenation of the census samples would be a tremendous boon to researchers. Our experience constructing a new sample of the 1880 census gave us further insight into the details of sample design and coding.5 It was clear that integrating the samples was a large and complicated task that required substantial funding to do properly.
The IPUMS project began in 1992 with a three-year grant from the National Science Foundation (grant number SBR-9118299). Some of the proposal's reviewers were skeptical about whether the census samples were sufficiently comparable to be integrated. There was also some sentiment that if we succeeded in what we proposed we might lower the bar sufficiently for the less sophisticated to gain access to the data and make mistakes. Fortunately, these were not the dominant opinions and the project was funded.
The timing of the IPUMS project coincided with a rapidly changing technological environment. When we first conceived of the project, we expected to disseminate the data in the traditional manner up to that point: magnetic tape distributed by the Inter-University Consortium for Political and Social Research (ICPSR) at the University of Michigan. By the time of our initial preliminary data release in late 1993, however, the Internet had radically altered these plans. From the beginning, we used the Internet as our sole means of data delivery. In fact, in the history of the project we never put a single byte of data on magnetic tape except for internal backups. Using the Internet, we could make the data directly accessible to researchers without any delays or request process. With continuous access and low dissemination costs the data could remain available on-line as we continued to develop and improve the database.
The original IPUMS was revised and completed in 1995 (Ruggles and Sobek 1995). Although the database and corresponding 800-page User's Guide probably exceeded most reasonable expectations, we had been forced to make some compromises along the way. In the tight budgetary climate of the early 1990s, NSF had not been able to fund fully the original project. Consequently, we requested and received an "accomplishment-based renewal" (grant number SBR-9422805). The new grant allowed us to expand the documentation, perform missing data allocation, and incorporate new census samples into the database. We were also able to correct some errors in the earlier version. The end product, IPUMS-2000, was released in late 1997 (Ruggles and Sobek 1997). We will correct any errors that are uncovered and will incorporate newly created census samples, but we expect IPUMS-2000 to be the last substantial revision we make to the database in the foreseeable future.
With the release of IPUMS-2000, we had compiled an impressively large data series with an equally imposing 3,000 pages of documentation. Unfortunately, the great size of the files and the scale of the documentation still posed a barrier to usage. The IPUMS was in danger of being to some degree the exclusive province of researchers associated with large data centers or otherwise well heeled in terms of computing resources. Once again, however, technological developments presented an opportunity to circumvent a serious potential bottleneck. In the course of our work on IPUMS-2000 we developed a rudimentary but effective system for extracting for analysis only select variables and cases from the database. The system could reduce multiple gigabytes of data to whatever size file was necessary and manageable for a given research project. It was clear that such a system was a logical complement to the IPUMS that would greatly expand its accessibility to researchers around the world.
In 1997 the National Institutes of Health and National Science Foundation jointly awarded a four-year grant for "Electronic Dissemination" of the IPUMS (grants HD34714 and SBR-9617820, respectively). Whereas the Internet had made distribution of the data files on physical media unnecessary, the World Wide Web made it possible to automate a data extraction procedure and to present the documentation on-line in electronic form. Researchers need never download the complete data files and can navigate the documentation without poring through multiple paper volumes. We have completed fully functional versions of both the extract and documentation systems and are continuing to develop them.
Strengths and Limitations
The principal strength of the census samples derives from their nature as microdata. Rather than summary data indicating how many persons possessed a particular characteristic at a given time or in a certain locality, census microdata give all the responses of individual persons and households transcribed from the census manuscripts. We know simultaneously for every person all of their personal characteristics and those of everyone with whom they resided. Each person and household is a separate record composed of numerically coded data; consequently, the samples require analysis with a statistical program. The payoff for this relative inconvenience is tremendous flexibility. Researchers can custom-design their own tabulations that do not depend on the categories pre-selected for them by the Census Bureau in the past. Even the modern Bureau is incapable of predicting or presenting all the tabulations required by researchers. The microdata often make it possible to overcome inconsistencies in published time series where, for example, the minimum age or sex of persons subject to a tabulation may have changed. The microdata also enable more sophisticated multivariate analyses exploring the relationships between characteristics at the individual or household level.
The great size of census microdata samples is another of their key strengths. Not even large modern surveys have enough cases to study small, geographically dispersed subpopulations such as Native Americans in a national context. Despite their size, however, the IPUMS samples are not useful for studying localities smaller than a substantial city. Nevertheless, the samples can still provide valuable context for local studies by allowing the combined analyses of similar small localities, like mill towns in the Northeast. From 1940 to 1990 some census years have greater sample densities, but no places smaller than those with a population of 100,000 or more can be identified, in order to protect the privacy of respondents. The samples have another important limitation: they are all drawn independently, so it is not possible to track the same individual from census to census to see how their characteristics changed over time. In other words, the IPUMS is a cross-sectional, not a longitudinal, database with respect to individuals.6
The primary goal of the IPUMS is to encourage analyses that incorporate multiple census years for the study of change over time. The census has always contained certain core questions that are generally comparable over the entire time span of the database. Other questions have come and gone. Table 2 describes many of the subject areas covered by the census since 1850 (many of these topics correspond to multiple variables in the database). Subjects such as personal income and migration status are confined to the second half of the twentieth century. Geographic detail, on the other hand, is actually superior in the historical samples, which did not have to suppress such information to ensure confidentiality.7 In fact, the detail available for most variables is typically superior in the pre-1940 historical samples, which sought to retain as much information as possible. Most of the samples prior to 1940 even include the names of the respondents and in some years their street address. Despite containing names, however, the samples are of little use for genealogy, since they contain only one percent of the population.
The IPUMS database and documentation aims to simplify use of census samples in combination, while the data extraction system allows researchers to create customized datasets with minimal effort. As we continue to add features to the extraction system, we aim to circumvent any need for programming knowledge, except for the most sophisticated analyses. Subsequent articles in this issue describe the data and documentation systems. Our approach to data dissemination is predicated on the notion of distributed data analysis. Individual researchers have access to ever more computing power on their desktops. The mainframe is gone for most social scientists. For many users, Internet data extraction and a personal computer are the only resources necessary to carry out their research. The size of the data files is increasingly a non-issue, especially with the extraction system enabling selection of only the necessary variables and subpopulations.
The largest remaining obstacle to more widespread use of the database is the need for familiarity with a statistical package. The IPUMS is an unprecedented resource for historical research, but relatively few historians are technically proficient at large-scale data analysis. Technology may again offer at least a partial solution. Programs such as SPSS for Windows are vastly easier to use than their predecessors, and we may reasonably expect continued improvement along these lines among all the statistical packages. In the meantime, economists and sociologists of a historical bent are likely to continue to outstrip historians in their use of the database.
There is a still larger potential audience of researchers wanting simple background statistics for largely non-quantitative applications: historians seeking context for local studies, teachers desiring descriptive numbers for lectures and discussion, and journalists seeking summary data addressing their shifting concerns. To some extent, these needs will increasingly be met through on-line data tabulation systems. The most impressive of these developed to date is Albert Anderson's Explore program, which performs tabulations on the largest IPUMS samples in only a few seconds.8 It is doubtful such systems can ever satisfy all the needs of sophisticated academic and public policy researchers, but they could suffice for many other applications.
Finally, we should note two profound limitations of the existing data series. First, the most recent data is from 1990, and is therefore almost ten years old. Second, the IPUMS provides observations of the American population only at ten-year intervals. Because of these limitations the database cannot be used to study many of the most pressing issues in social and behavioral science, such as the impact of recent immigration or increasing married female workforce participation. We discuss the solution to these problems in the final section of this essay.
From IPUMS-95 to IPUMS-2000
The change from IPUMS-95 to IPUMS-2000 was a comprehensive revision. New preliminary samples of 1860 and 1870 and an expanded and improved version of the 1920 census sample were incorporated into the database. Numerous variables were added, and the coding schemes for several important variables such as relationship and birthplace were improved and rationalized. Among the highlights are much-improved algorithms linking wives to husbands and parents to children. Table 3 provides a list of substantially altered variables along with brief explanatory notes. In addition to the substantive variables, we added a number of data quality flags previously excluded and corrected errors in flag coding and record layout. Most results from IPUMS-95 are unlikely to be much affected by the revisions, but any user of the older version should be aware of these changes.
The largest data revision in IPUMS-2000, was the allocation of virtually all missing and illegible data. We have used logical editing and "hot deck" probabilistic editing procedures to allocate missing, illegible and inconsistent data in all the censuses from 1850 to 1920.9 The Census Bureau used the same allocation techniques for the period since 1940. Allocation of missing and inconsistent data significantly increases the precision of sample estimates and makes the samples simpler to use. Data quality flags identify the allocations so that a researcher can choose not to use them. We have documented the missing data allocation procedures for all census years. For 1980 and 1990, the Census Bureau never published the allocation procedures, but we were able to reconstruct them from a series of internal memos provided to us by the Bureau.10
The documentation has changed even more dramatically than the data, growing from one 800-page guide to five volumes totaling 3000 pages. Two supplementary volumes in addition to the User's Guide are designed to make any reference to the original sample codebooks unnecessary. The User's Guide provides variable descriptions, codes, frequencies, and other basic information essential for using the database. The User's Guide Supplement (Volume 2) contains geographic tools such as maps, tables of historical changes in metropolitan areas and detailed supplementary variable information. IPUMS-2000, Volume 3: Counting the Past, has all enumerator instructions, copies of enumeration forms, capsule histories of the censuses, and descriptions of sample creation and data allocation procedures. Two further technical volumes (Vols. 4 and 5) detail how original variables were assigned new values by the IPUMS computer program. All of these volumes are available on-line in hypertext format, and we are continuing to improve the electronic formatting to enhance their usability.
Value Added Over the Original Census Samples
Much of the value of the IPUMS for historical and long-term analysis arises from compatible variable treatment and integrated documentation across census years. The techniques we used to achieve this compatibility are described elsewhere in this issue and in the 1995 special issue of Historical Methods. Beyond the issues of compatibility, however, the IPUMS offers a number of entirely new features. Most of these are minor conveniences, but others are more substantial. The paragraphs that follow describe some of the most important reasons the IPUMS is easier to use than any previous census microdata.
The IPUMS retroactively identifies metropolitan areas in every census year in the database applying the criteria used in 1950, when the concept was first employed by the census. We also reconstruct the pre-1940 census concept of metropolitan districts for the historical samples (see the article by Gardner in this issue). We also have for the first time identified the county composition of every metropolitan area from 1850 to 1990, and included all maps associated with the varying geographic divisions identified in the original samples.
We include a set of consistently constructed family interrelationship pointer variables for all years; they greatly aid in the design of family-related measures. Of the original samples, only 1910 had such a feature, and the links were not always consistently made, since in many cases they were performed by hand rather than computer.11 With researchers using the same set of interrelationship variables, the IPUMS removes the chance that results of two researchers may simply be an artifact of two different linking procedures.
We emphasize the utility of the IPUMS for historical applications, and indeed that was foremost in our minds when we envisioned the project. But researchers interested in only the most recent census years-even only 1990-have much to gain by using the IPUMS. We have corrected dozens of small errors in the Census Bureau samples and documentation, and added convenient features such as an unweighted version of the 1990 sample.
The IPUMS geographic codes are much easier to use than those provided by the Census Bureau. For example, the 1980 and 1990 samples do not identify city of residence. Users are forced to recode a complex seven-digit code to reconstitute cities (five digits in 1980), and the Bureau does not even document which cities are fully identifiable by means of this cumbersome procedure.12 The IPUMS includes a consistent code for city across all samples, and we use it to identify city of residence five years ago and city of work in addition to city of current residence. We also discovered a way to identify urban-rural status in the 1990 sample, which otherwise lacked this basic variable.13
A second example of the advantages of the IPUMS over the Census Bureau samples concerns the family and poverty variables. The 1970, 1980 and 1990 Census Bureau samples do not identify families unrelated to the householder, such as families composed of boarders or lodgers. Moreover, the 1970 and 1980 samples fail to identify most subfamilies, owing to a programming error. Our family interrelationship variables are a significant improvement in both these areas. The failure to identify families unrelated to the householder also led to a major flaw in the 1990 poverty variable. Children unrelated to the householder were simply ignored for poverty purposes in the 1990 sample; there are no unrelated children in poverty. In addition, the parent of such a child was assigned the poverty status (percent of poverty level) for a single adult, not a family of two or more. So the original 1990 PUMS greatly understates poverty for a group of persons who are of particular interest to policy analysts. The IPUMS rectifies these deficiencies and includes a fully compatible measure of poverty for all years in which income is available.14
The State of the IPUMS Project
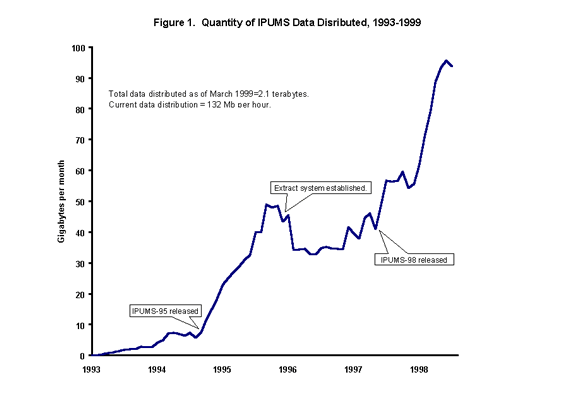
If usage is any guide, the IPUMS project is already a great success. We have distributed over 2 terabytes (thousands of gigabytes) of data and are presently disseminating an average of 110 megabytes per hour, 24 hours per day. Figure 1 shows our average monthly rate of data distribution since we began disseminating data over the Internet in 1993. The first major increase coincides with the availability of IPUMS-95 in the summer of that year. The drop from the first peak in early 1996 reflects the fact that many major data users had already obtained the files by that time. A bigger factor in the drop, however, is probably the introduction of the web-based data extraction system in May 1996, which decreased the file sizes researchers needed to download. The more recent increase simply demonstrates the growing user base for the system.
Even though the database has only been widely distributed since late 1995, it has already served as the basis of three books, ten completed dissertations, and over 45 articles, many of which appeared in top journals such as the American Economic Review, the American Sociological Review, the American Historical Review, Social Forces and Demography (see our bibliography for a list of publications). The user base continues to grow, with some 500 new registered users during the past six months. In a very brief period the IPUMS has become one of the most widely used databases in American social science.
The IPUMS project is funded until 2001, and we expect to accomplish a great deal in the intervening period. Most of our efforts will be concentrated on dissemination: improving the data extraction system and the electronic version of the documentation. Our efforts in both these areas are discussed in detail in subsequent articles in this Special Issue.
A key aspect of our dissemination strategy involves mirror extraction sites at other institutions. We are replicating the current system at the University of Michigan Population Studies Center, the University of Wisconsin Center for Demography and Ecology, and ICPSR. Once we have ironed out the process, we hope additional institutions will participate. Our future plans also include a possible version of the hypertext documentation and extraction system installed on a removable media device not dependent on any network connection.
With NIH funding, we have begun entering a new one percent sample of the 1900 census that will replace Preston's original 1-in-760 sample, which was always somewhat incompatible with the other census years because of its sample design. The new sample will be added to the database, as will the completed versions of 1860 and 1870. If funding permits, by 2008 we hope to have created new samples of 1910 and 1930.
Future Development
Our most ambitious new undertaking is a ten-year proposal to expand the IPUMS paradigm to a broad range of additional individual-level datasets from both the United States and elsewhere. The existing IPUMS is modest by comparison with our proposed endeavor: we plan to build a database with some 670 samples drawn from twenty-one countries, including about 500 million records and requiring some 250 gigabytes in uncompressed form. The original IPUMS required about 130,000 data transformations; the new database will involve over a million. We estimate that we will need to write the equivalent of about 14,000 pages of documentation, compared with only 3,000 pages in the current IPUMS. This increase in scale will necessitate a proportionate increase in complexity, so we will need to develop new navigation and extraction tools to keep access to the data and documentation simple.
The new project will incorporate domestic and international data from a variety of sources. We will start with the U.S. census samples for the period 1850 through 1990 in the current IPUMS. Then, we will add additional domestic samples to allow detailed study of the American population in the late twentieth and early twenty-first century. Specifically, we will incorporate 528 monthly samples of the Current Population Survey for the period 1964 through 2008, the 2000 Census Public Use Microdata Sample, and the American Community Surveys for the period 2000-2008.
The new database will be applicable to a far broader range of problems than the existing series. The addition of data from the Current Population Survey will allow us to provide monthly samples from 1964 right up to the present. The data from the American Community Survey, which will begin in 2000, will provide high-density samples on an annual basis suitable for the study of small population subgroups and specific geographic areas. These data will find a broad range of applications for public policy and the analysis of contemporary social and economic conditions in temporal context.
In addition to the new U.S. samples, we propose to incorporate approximately 100 contemporary and historical census and survey microdata files from 20 countries into the data series. The international data fall into two categories. For some countries, such as Canada, Britain, and China, we will incorporate public-use census or survey samples that already exist, just as we have done for the United States. While these data are generally reasonably well-documented and are usually straightforward, they pose complexities we have not previously encountered because of national differences in census concepts, cultural practices, and language. For other countries, no public-use census files presently exist. In these instances, we will create new anonymized samples drawn from surviving census tapes that were used to construct aggregate census tabulations for publication.
The globalization of the IPUMS paradigm to twenty-one countries, each of which will also incorporate a chronological dimension, will open up exciting new analytic possibilities. For most of these countries, the new database will incorporate multiple censuses spanning the period from 1960 to 2000. For some countries-such as Canada, Norway, Britain, and Argentina-the chronological depth is far greater, stretching back into the nineteenth century. The inclusion of international data will allow investigations of social change across space as well as through time. Most of the data focus on the last one-third of the twentieth century, a time of unprecedented economic change and international population movement.
We believe that the creation of a global microdata archive will make a permanent and substantial contribution to the infrastructure of social and behavioral science. The potential uses of the new database are many. Among key research areas are the comparative study of economic inequality, industrial and occupational structure, household and family composition, the household economy, female labor force participation, urbanization, internal migration, immigration, nuptiality, fertility, and education. In each case, these topics can be studied across time as well as across countries. Analysts of immigration to the United States will be able to compare the characteristics of newcomers with those they left behind. Students of the African, British, and Spanish diasporas will be able to compare the characteristics of people with the same ethnic origin in a wide variety of countries, and to assess how those characteristics have changed. Researchers working on the impact of NAFTA will be able to carry out multivariate analyses using pooled microdata from Canada, Mexico, and the United States spanning the last quarter of the twentieth century. Just as the existing IPUMS has stimulated research on long-run social and economic change, the new project has the potential to stimulate new research that transcends national boundaries and static interpretation.
ENDNOTES:
- This article appeared in Historical Methods, Volume 32, Number 3, Pages 102-110, Summer 1999. Reprinted with Permission of the Helen Dwight Reid Educational Foundation. Published by Heldref Publications, 1319 18th St. N.W. Washington, D.C. 20036-1802. Copyright 1999.
- The project is currently funded by NSF grant SBR-9617820 and NIH grant HD34714.
- The 1940 and 1950 samples were designed by a research team at the University of Wisconsin in the early 1980s, but the data input and processing were carried out by Census Bureau staff in Washington.
- We begin the series in 1850 because that is the first census with individual-level-rather than merely household-level-information. 1850 is therefore the earliest year in which it is possible to create a national individual-level census file comparable to subsequent samples.
- Ironically, even the 1880 sample that we created was not completely compatible with any samples that came before (Ruggles and Menard 1994).
- Joseph Ferrie (1996) has developed a procedure for linking men in the 1850 sample to the 1860 census manuscripts, but it is extremely laborious.
- Available geographic detail varies widely among the modern samples subject to confidentiality rules. The smallest unit available in 1940 and 1950 is State Economic Area: groups of counties within states that shared a similar economic base. The IPUMS replicates these groupings in the samples before 1940. The worst sample for geography is 1960, which provides no information below the level of state (metropolitan and urban status are also given, though precise location is missing). 1970 provides "county groups" which combine counties into units that meet a 250,000 population threshold. 1980 and 1990 define geographic units of varying composition ("county groups" and "public use microdata areas," respectively) that have at least 100,000 population. As long as the units have the requisite population in 1980 and 1990, the geographic units can be as precise as sections of cities or combinations of specific communities within counties.
- The URL for the Explore project is http://www.pdq.com. The Census Bureau's Ferret system and the Survey Documentation & Analysis project at Berkeley also offer interactive tabulation systems on the Internet, and the Census Bureau is devoting substantial resources to the development of a more sophisticated on-line tabulation system; see http://www.census.gov and http://csa.berkeley.edu. Still, it remains to be seen how elaborate census data delivery systems can become and still meet confidentiality requirements. Frey and associates at the University of Michigan present another data access model (Frey 1997). They have incorporated a reduced version of the census data with a simple statistical package that walks students through a series of tabulations designed to explore historical social change.
- Newly allocated variables include county, urban status, city, city population, metropolitan area, farm, ownership, mortgage, duration of marriage, children ever born, children surviving, citizenship, year naturalized, year immigrated, years in U.S., mother tongue, language, school, literacy, employment status, occupation, industry, class of worker, period unemployed, age in months and month of birth.
- IPUMS-2000, Volume 3: Counting the Past, documents the allocation procedures we employed for the period 1850 to 1920 and describes the methods used by the Census Bureau from 1940 to 1990.
- The IPUMS retains these 1910 links in their original form as separate variables. In some cases these hand links are superior to those performed by computer, but they cannot be consistently applied to the other census samples.
- In both 1980 and 1990 users must combine state and county group/PUMA to identify localities. Interpreting these codes entails referring to large machine-readable "equivalency files" that are not part of the sample codebooks. The process is even more complex for place of work and migration purposes in 1990. Only the first 3 digits of PUMA are used (even though 5 are allocated in the original sample record layout), so the equivalency files require considerable interpretation.
- Farm status as contained in the 1990 "farm" variable was only applicable to rural households, thus enabling us to identify urban/rural status. The results correspond to published 1990 statistics on urban status.
- Poverty is calculated for the period 1950 to 1990. Incomes in all years are converted to 1990 dollars using the urban consumer price index, and the 1990 formula for calculating poverty status is then applied without alteration. The original 1990 sample also truncated the poverty measure rather than rounding-a subtle point perhaps, but one that can make a difference at the thresholds.
References
Ferrie, J. 1996. A new sample of males linked from the public use microdata sample of the 1850 U.S. federal census of population to the 1860 U.S. federal census manuscript schedules. Historical Methods 29: 141-156.
Frey, W. 1997. Investigating change in American society: Exploring social trends with U.S. census data and StudentChip. With Cheryl First. Belmont, CA: Wadsworth.
McCaa, R. 1993. Gender in the melting pot: Marital assimilation in New York City, 1900-1980. Journal of Interdisciplinary History 24: 207-231.
Ruggles, S. 1988. The demography of the unrelated individual, 1900-1950. Demography 25: 521-36.
Ruggles, S. and R. Goeken. 1992. Race and multigenerational family structure, 1900-1980. In The Changing American family: Sociological and demographic perspectives, edited by S. J. South and S. E. Tolnay, 15-42. Boulder, CO: Westview Press.
Ruggles, S. and R. R. Menard et al. 1994. 1880 Public use microdata sample: User's guide and technical documentation. Minneapolis: University of Minnesota.
Ruggles, S. and M. Sobek. 1995. Integrated public use microdata series: Version 1.0. Minneapolis: University of Minnesota.
_____. 1997. Integrated public use microdata series: Version 2.0. Minneapolis: University of Minnesota.
Stevens, D.A. 1990. New evidence on the timing of early life course transitions: The United States 1900 to 1980. Journal of Family History 15: 163-78.
| Table 1. Characteristics of National Census Microdata Files by Year of Creation* | |||||||
|---|---|---|---|---|---|---|---|
| Census Year | Year Released | Sample Densities | Creator | Number of Records (thousands) | Number of Variables |
IPUMS File Size |
|
| Household | Person | ||||||
| 1960 | 1964 | 1/1000 | Census Bureau | 58 | 178 | 130 | 79 Mb |
| 1970 | 1972 | (6) 1/100 | Census Bureau | 4464 | 12180 | 206 | 5576 Mb |
| 1960 | 1973 | 1/100 | Census/DUALabs | 579 | 1780 | 141 | 790 Mb |
| 1900 | 1980 | 1/760 | Preston | 208 | 870 | 115 | 361 Mb |
| 1980 | 1983 | 1/20, (2) 1/100 | Census | 6595 | 15871 | 276 | 7526 Mb |
| 1940 | 1984 | 1/100 | Winsborough/Census | 391 | 1351 | 174 | 584 Mb |
| 1950 | 1984 | 1/100 | Winsborough/Census | 461 | 1922 | 170 | 798 Mb |
| 1910 | 1989 | 1/250 | Preston | 89 | 366 | 125 | 152 Mb |
| 1880 | 1990 | 1/1000 | Ruggles | 10 | 50 | 123 | 20 Mb |
| 1850 | 1992 | 1 /200 | Menard/Ruggles | 18 | 99 | 92 | 39 Mb |
| 1990 | 1992 | 1/20, 1/100 | Census Bureau | 6634 | 15000 | 252 | 7247 Mb |
| 1850 | 1994 | 1/100 | Menard/Ruggles | 37 | 198 | 92 | 79 Mb |
| 1880 | 1994 | 1/100 | Ruggles | 107 | 503 | 123 | 204 Mb |
| 1920 | 1995 | 1/330 | Ruggles | 86 | 346 | 122 | 144 Mb |
| 1860 | 1998 | 1/500 | Ruggles | 13 | 71 | 94 | 28 Mb |
| 1870 | 1998 | 1/500 | Ruggles | 16 | 86 | 94 | 34 Mb |
| 1920 | 1999 | 1/100 | Ruggles | 257 | 1037 | 122 | 433 Mb |
| 1860 | 2001 | 1/100 | Ruggles | 66 | 354 | 94 | 141 Mb |
| 1870 | 2001 | 1/100 | Ruggles | 80 | 428 | 94 | 170 Mb |
| 2000 | 2002 | 1/20 | Census Bureau | c. 7000 | c. 14000 | 251 | 6764 Mb |
| 1900 | 2003 | 1/100 | Ruggles | 208 | 870 | 115 | 361 Mb |
| 1910 | 2004 | 1/100 | Ruggles | 222 | 915 | 125 | 381 Mb |
| 1930 | 2007 | 1/100 | Ruggles | 282 | 1172 | 122 | 487 Mb |
| TOTAL 32,400 Mb | |||||||
| NOTE: Table 1 summarizes data available at the time the article was written. New samples have been added and others are under construction at the Minnesota Population Center. Check the FAQ for a current list of available samples. | |||||||
Table 2. Availability of Select Subject Areas, 1850-1990
| Year | 1850 | 1860 | 1870 | 1880 | 1900 | 1910 | 1920 | 1940 | 1950 | 1960 | 1970 | 1980 | 1990 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Household Record | |||||||||||||
| State | X | X | X | X | X | X | X | X | X | X | X | X | X |
| County | X | X | X | X | X | X | X | . | . | . | . | . | . |
| County group/microdata area | . | . | . | . | . | . | . | . | . | . | X | X | X |
| State economic area | X | X | X | X | X | X | X | X | X | . | . | . | . |
| Metropolitan area | X | X | X | X | X | X | X | X | X | . | X | X | X |
| City | X | X | X | X | X | X | X | X | X | . | . | X | X |
| Size of place | X | X | X | X | X | X | X | X | X | . | . | X | X |
| Urban/rural status | X | X | X | X | X | X | X | . | . | X | X | X | X |
| Farm | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Ownership of dwelling | . | . | . | . | X | X | X | X | . | X | X | X | X |
| Mortgage status | . | . | . | . | X | X | X | . | . | . | . | X | X |
| Value of house or property | . | . | . | . | . | . | . | X | . | X | X | X | X |
| Monthly rent | . | . | . | . | . | . | . | X | . | X | X | X | X |
| Total family income | . | . | . | . | . | . | . | . | X | X | X | X | X |
| Person Record | |||||||||||||
| Relationship to household head | . | . | . | X | X | X | X | X | X | X | X | X | X |
| Age | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Sex | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Race | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Marital status | . | . | . | X | X | X | X | X | X | X | X | X | X |
| Age at first marriage | . | . | . | . | . | . | . | X | . | X | X | X | . |
| Duration of marriage | . | . | . | . | X | X | . | . | X | . | . | . | . |
| Times married | . | . | . | . | . | X | . | X | X | X | X | X | . |
| Children ever born | . | . | . | . | X | X | . | X | X | X | X | X | X |
| Birthplace | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Parents' birthplaces | . | . | . | X | X | X | X | X | X | X | X | . | . |
| Ancestry | . | . | . | . | . | . | . | . | . | . | . | X | X |
| Years in the United States | . | . | . | . | X | X | X | . | . | . | X | X | X |
| Mother tongue | . | . | . | . | . | X | X | X | . | X | X | . | . |
| Language spoken | . | . | . | . | . | X | . | . | . | . | . | X | X |
| School attendance | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Educational attainment | . | . | . | . | . | . | . | X | X | X | X | X | X |
| Literacy | X | X | X | X | X | X | X | . | . | . | . | . | . |
| Employment status | . | . | . | . | . | X | . | X | X | X | X | X | X |
| Occupation | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Industry | . | . | . | . | . | X | X | X | X | X | X | X | X |
| Class of worker | . | . | . | . | . | X | X | X | X | X | X | X | X |
| Weeks worked last year | . | . | . | . | . | . | . | X | X | X | X | X | X |
| Weeks unemployed | . | . | . | X | X | X | . | X | X | . | . | . | . |
| Total personal income | . | . | . | . | . | . | . | . | X | X | X | X | X |
| Wage and salary income | . | . | . | . | . | . | . | X | X | X | X | X | X |
| Value of personal or real estate | X | X | X | . | . | . | . | . | . | . | . | . | . |
| Migration status | . | . | . | . | . | . | . | X | X | X | X | X | X |
| Veteran status | . | . | . | . | . | X | . | X | X | X | X | X | X |
| Name | X | X | X | X | . | . | X | . | . | . | . | . | . |
| NOTE: X = available in that census year. | |||||||||||||
Table 3. IPUMS-98 New and Revised Variables: Select Listing
| New Variables |
|---|
| Labor force status |
| constructed with a consistent age universe for all years. Based on occupation before 1940 and employment status 1940-1990. |
| Poverty status |
| uses 1990 income and family composition criteria to calculate percent of poverty level for all families, secondary families, and individuals for all applicable years (1950-1990). |
| City of residence five years ago |
| based on state and county group/PUMA five years ago. |
| Metro of residence five years ago |
| based on state and county group/PUMA five years ago. |
| Place of work: city |
| based on state and county group/PUMA. |
| Place of work: metropolitan area |
| based on state and county group/PUMA. |
| Imputed mother, father, and spouse linking variables |
| constructed identically for 1850-1880, and 1910 to enable consistent comparisons with those years in which relationship to head is not available (1850-1870). |
| Number of households sampled |
| in years with dwelling-level samples (1850-1880, 1920), identifies the number of separate households from a dwelling that are included in the data. Enables analysis of multi-household dwellings. |
| Revised Variables |
| Family interrelationship variables |
| significantly improved the pointer variables linking husbands to wives and parents to children. |
| Metropolitan area |
| changed the classification to match 1990 FIPS codes, with one extra digit for historical change. |
| City |
| fixed several errors and added more identifiable 1980 and 1990 cities. |
| Occupation, 1950 |
| much improved coding in the 1920 sample. |
| Industry |
| recoded 1910 into numeric from alphabetic format. |
| Industry, 1950 |
| inferred industry from occupation responses in 1850-1880, and improved 1920 dramatically. |
| Weights |
| weight variables now reflect the actual population counts rather than theoretical sample densities. |
| Group quarters |
| reclassified some households to enhance comparability |
| Group quarters type |
| significantly revised the classification to make categories more consistent. |
| Relationship |
| significantly revised and rationalized. |
| Birthplace |
| rationalized the coding scheme, changing some foreign-born codes. |
| Spanish surname |
| identified in all census years that contain surname |
| Migration and place of work variables |
| renamed, added, and changed numerous variables. |
Supported By
![]()
![]()
![]()
![]()
![]()